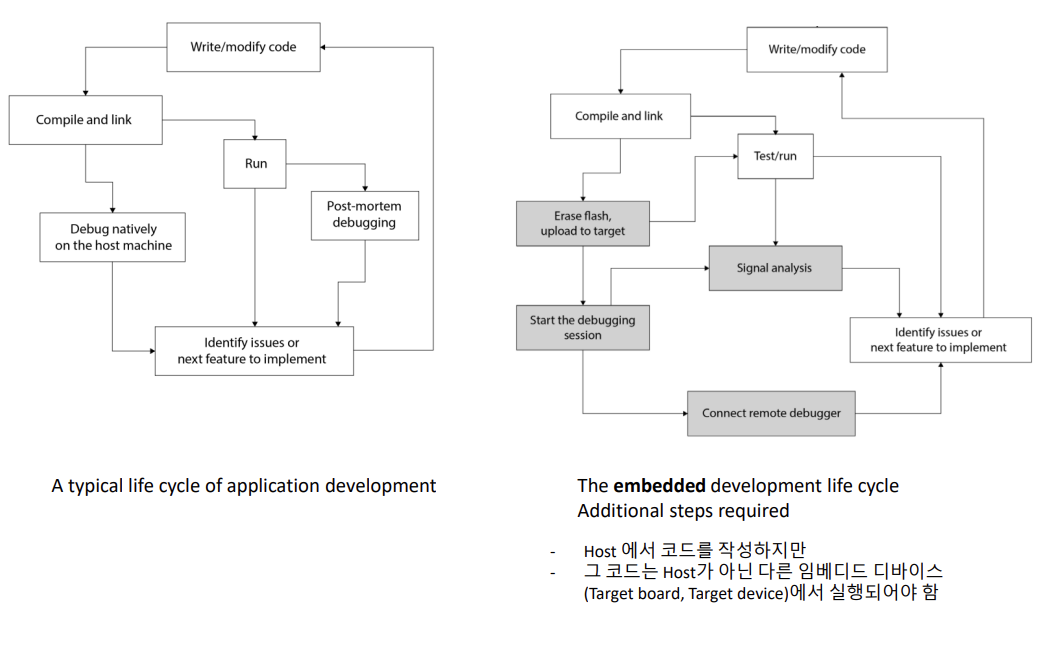
일반적인 응용 프로그램 개발 및 임베디드 개발 수명주기 사이에는 몇 가지 중요한 차이점이 있습니다.
플랫폼과 하드웨어: 응용 프로그램 개발은 주로 특정 플랫폼(예: 웹, 데스크톱, 모바일)에 대해 이루어지지만, 임베디드 시스템은 특정 하드웨어에 대한 소프트웨어 개발로 진행됩니다. 임베디드 시스템은 종종 리소스 제한이 있으며, 하드웨어와의 직접적인 통합이 필요합니다.
환경 및 도구: 응용 프로그램 개발은 주로 표준 개발 환경과 도구(예: IDE, 테스트 프레임워크)를 사용하지만, 임베디드 시스템 개발은 하드웨어 시뮬레이션, 디버깅 및 테스트를 위해 특수한 도구와 환경이 필요합니다.
속도와 성능: 응용 프로그램은 종종 사용자 경험에 중점을 두며 빠른 개발과 배포가 중요합니다. 반면에 임베디드 시스템은 종종 실시간 및 고성능 요구사항이 있으며, 하드웨어와의 직접적인 상호작용으로 인해 속도와 성능을 고려해야 합니다.
수명주기 및 유지보수: 일반적으로 임베디드 시스템은 긴 수명주기를 가지며, 제품 출시 후에도 주기적인 업데이트 및 유지보수가 필요합니다. 반면에 응용 프로그램은 더 짧은 수명주기를 가질 수 있으며, 빠른 변경 및 업데이트가 일반적입니다.
이러한 차이점들은 개발 프로세스, 도구 및 기술 선택 등에 영향을 미치며, 각각의 유형의 소프트웨어 개발에 대해 고려해야 할 요소들입니다.
임베디드 시스템의 디버깅은 주로 개발자가 개발한 소프트웨어를 실행하는 임베디드 시스템 자체에서 이루어집니다. 일반적으로 다음과 같은 방법으로 디버깅이 수행됩니다.
인라인 디버깅: 개발자는 임베디드 시스템에 디버깅용 코드 또는 디버깅 도구를 포함하여 프로그램을 개발할 수 있습니다. 이를 통해 프로그램 실행 중에 중단점을 설정하고 변수 값을 확인하여 버그를 해결할 수 있습니다.
시리얼 콘솔 디버깅: 임베디드 시스템에는 종종 시리얼 포트가 있으며, 개발자는 이를 통해 디버깅 메시지를 출력하고 디버깅 명령을 보낼 수 있습니다. 이를 통해 프로그램 실행 중의 상태를 실시간으로 확인할 수 있습니다.
JTAG 디버깅: 임베디드 시스템의 주변에는 종종 JTAG(Join Test Action Group) 인터페이스가 있습니다. 이를 통해 개발자는 임베디드 시스템의 내부 상태를 실시간으로 모니터링하고 디버깅할 수 있습니다. JTAG를 통해 프로세서의 레지스터, 메모리 및 다른 하드웨어 구성 요소에 접근할 수 있습니다.
실제 하드웨어 디버깅: 일부 임베디드 시스템은 실제 하드웨어 디버깅을 지원합니다. 이는 특수한 디버깅 하드웨어를 사용하여 실제 하드웨어 상태를 모니터링하고 디버깅하는 것을 의미합니다.
이러한 디버깅 방법들은 개발자가 임베디드 시스템에서 발생하는 문제를 식별하고 해결하는 데 도움이 됩니다.
오브젝트 파일(Object file)은 컴파일된 소스 코드의 결과물로, 주로 기계어 코드와 해당 코드에 대한 기호(symbol) 정보를 포함하고 있습니다. 일반적으로 컴파일러나 어셈블러에 의해 생성됩니다. 이러한 오브젝트 파일은 하나 이상의 소스 코드 파일로부터 생성되며, 주로 여러 오브젝트 파일을 링크(Link)하여 실행 가능한 바이너리(executable) 파일을 생성합니다.
오브젝트 파일은 크게 두 가지 형태로 나뉩니다:
1. **목적 파일(Object files)**: 컴파일된 소스 코드의 중간 결과물로, 기계어 코드와 해당 코드에 대한 기호 정보를 포함합니다. 목적 파일은 일반적으로 컴파일된 단일 소스 코드 파일에 해당하며, 프로그램의 특정 부분을 나타냅니다.
2. **라이브러리 파일(Library files)**: 여러 목적 파일의 집합으로, 주로 코드의 재사용을 위해 사용됩니다. 라이브러리 파일은 특정 기능이나 기능 집합을 제공하는 함수나 모듈의 모음입니다.
오브젝트 파일은 대부분 특정 플랫폼이나 아키텍처에 종속적이며, 다양한 형식이 있을 수 있습니다. 예를 들어, Unix 및 Linux 시스템에서는 ELF(Executable and Linkable Format) 형식이 일반적이고, Windows 시스템에서는 COFF(Common Object File Format)나 PE(Portable Executable) 형식이 사용됩니다.
오브젝트 파일은 링커(Linker)에 의해 하나로 결합되어 최종 실행 파일이나 라이브러리 파일이 생성됩니다. 링크 과정에서는 각각의 오브젝트 파일에 있는 기호들이 해결되고, 실행 가능한 형식으로 결합됩니다.
Linker
- 여러개의 object file을 하나의 binary file로 합치는 작업을 한다.
- 이때, static library, synamic library들을 포함시킨다. (함수가 너무 많을 때, Library에 따로 넣어준다.)
ELF Format
- 실행 파일,목적 파일,공유 라이브러리 그리고코어 덤프를 위한 표준 파일 형식 (Default Standard Format for programs, objects, shared libraries, and even GDB core dumps on many Unix and Unix-like system)
- The host OS can execute it by loading the instructions in RAM and allocating the space for the program data
각 ELF 파일은 하나의 ELF 헤더와 파일 데이터로 이루어진다.
0개 또는 그 이상의세그먼트들을 정의하는 프로그램 헤더 테이블
0개 또는 그 이상의 섹션들을 정의하는 섹션 헤더 테이블
프로그램 헤더 테이블 또는 섹션 헤더 테이블의 엔트리들에 의해 참조되는 데이터
ELF 파일은 두 관점을 갖는다
: 프로그램 헤더는 런타임 시 사용되는 세그먼트들을 보여주고, 섹션 헤더는 바이너리의 섹션들의 집합을 나열한다.
ELF(Executable and Linkable Format)는 컴퓨터 파일 포맷의 하나로, 주로 Unix 및 Unix-like 시스템에서 실행 파일, 오브젝트 파일, 공유 라이브러리 등을 저장하는 데 사용됩니다. ELF 포맷은 다양한 CPU 아키텍처에서 사용되며, 이식성이 뛰어나고 유연성이 높은 특징을 가지고 있습니다.
ELF 파일은 크게 세 가지 섹션으로 구성됩니다:
1. **헤더(Header)**: - ELF 파일의 전반적인 정보를 포함합니다. - 파일의 형식(32비트 또는 64비트), 섹션 테이블 및 프로그램 헤더 테이블의 위치 등의 메타데이터를 포함합니다.
2. **섹션(Sections)**: - 코드, 데이터, 심볼(symbol), 디버깅 정보 등을 담고 있는 섹션들입니다. - 각 섹션은 특정 종류의 데이터를 저장하며, 예를 들어 `.text` 섹션에는 실행 가능한 기계어 코드가 저장되고, `.data` 섹션에는 초기화된 데이터가 저장됩니다.
3. **프로그램 헤더(Program Header)**: - 실행 가능한 ELF 파일에만 포함되며, 파일이 메모리에 로드될 때 어떻게 로드되고 실행되어야 하는지를 지정합니다. - 각 프로그램 헤더는 섹션의 로드 주소, 크기, 권한 등의 정보를 포함합니다.
ELF 포맷은 다양한 운영 체제에서 사용되며, 리눅스와 같은 Unix 계열의 운영 체제에서는 주요 실행 파일 포맷으로 사용됩니다. ELF 파일은 이식성이 뛰어나고, 디버깅 및 동적 링킹과 같은 기능들을 지원하여 유연한 소프트웨어 개발을 가능하게 합니다.
1. ELF 헤더 : 파일의 구성을 나타내는 로드맵과 같은 역할을 하며, 첫 부분을 차지
2. 섹션 : 링킹을 위한 object 파일의 정보를 다량으로 가지고 있으며, 이에 해당하는 것으로는 명령, 데이터, 심볼 테이블, 재배치 정보 등이 들어간다.
3. 프로그램 헤더 테이블(옵션) : 시스템에 어떻게 프로세스 이미지를 만들지를 지시
프로세스의 이미지를 만들기 위해서 사용되는 파일은 반드시 프로그램 헤더 테이블을 가져야하며, 재배치 가능 파일의 경우엔 가지지 않아도 된다.
4. 섹션 헤더 테이블 : 파일의 섹션들에 대해서 알려주는 정보를 포함
모든 섹션은 이 테이블에 하나의 엔트리(entry)를 가져야 한다.
각각의 엔트리는 섹션 이름이나, 섹션의 크기와 같은 정보를 제공해 준다.
만약 파일이 링킹하는 동안 사용된다면, 반드시 섹션 헤더 테이블을 가져야 하며, 다른 object파일은 섹션 헤더 테이블을 가지고 있지 않을 수도 있다.
gcc -c hello.c //generate hello.o
gcc -o helloworld hello.o world.o //generate ELF file helloworld //In helloworld, symbols in hello.o and world.o
GNU Compiler Collection (GCC)
: 운영 체제의 하나이자 컴퓨터 소프트웨어의 모음집 / an optimizing compiler produced by the GNU Project supporting various programming languages, hardware architectures and operating systems
GCC는 임베디드 시스템을 빌드하기 위한 reference toolchain 중 하나라고 보면 된다.
Visual Studio와 같은 IDE를 대체하는 개념!
*cross compiler
Cross Compiler는 특정한 운영 체제나 아키텍처를 타겟으로 하는 프로그램을 개발할 때 사용되는 컴파일러입니다. 보통 호스트 시스템과 타겟 시스템이 서로 다른 경우에 사용됩니다.
일반적으로 개발자가 사용하는 시스템은 호스트 시스템이며, 이 시스템에서는 개발된 프로그램을 컴파일하고 실행할 수 있습니다. 그러나 때로는 호스트 시스템과 타겟 시스템이 서로 다른 아키텍처를 사용하거나, 다른 운영 체제를 가지고 있을 수 있습니다. 이런 경우에는 호스트 시스템에서 컴파일된 프로그램은 타겟 시스템에서 실행되지 않습니다.
이런 문제를 해결하기 위해 Cross Compiler가 사용됩니다. Cross Compiler는 호스트 시스템에서는 개발된 프로그램을 타겟 시스템에서 실행 가능한 형태로 컴파일할 수 있도록 해줍니다. 즉, Cross Compiler는 호스트 시스템에서 타겟 시스템을 위한 실행 파일을 생성하는 데 사용됩니다.
예를 들어, 임베디드 시스템 개발에서는 보통 호스트 시스템은 PC나 노트북과 같은 일반적인 컴퓨터이고, 타겟 시스템은 마이크로컨트롤러나 임베디드 보드와 같은 작은 장치일 수 있습니다. 이런 경우에는 Cross Compiler를 사용하여 호스트 시스템에서는 타겟 시스템을 위한 소프트웨어를 개발하고 테스트할 수 있습니다.
<강의 자료 내 cross compiler 예시> 컴파일 명령어 예시Linking과 Binary format conversion 명령어 예시
'Make : a build automation tool'
- Build system for embedded SW : Make, CMake, Bitbake
- to automate the steps required to created binary images from the sources, check the dependencies for each component and execute the steps in the right order
이 make 명령어는 임베디드 소프트웨어를 빌드하기 위해 필요한 단계들을 자동화하는 도구입니다. 이를 통해 소스 코드로부터 이진 이미지를 생성하는 과정을 자동화하고, 각 구성 요소의 종속성을 확인하여 올바른 순서대로 단계를 실행합니다. 구체적으로 설명하자면, 이 make 명령어는 다음과 같은 작업을 수행합니다:
1. **소스 코드 컴파일**: 빌드 프로세스의 첫 번째 단계는 소스 코드를 컴파일하여 오브젝트 파일을 생성하는 것입니다. 이는 소스 코드를 기계어로 변환하여 실행 가능한 프로그램을 만드는 과정입니다.
2. **의존성 검사**: 각 구성 요소의 종속성을 확인합니다. 이는 각 소스 파일이나 모듈이 다른 파일 또는 라이브러리에 의존하는지 여부를 확인하는 것을 의미합니다. 종속성을 검사하여 소스 파일이나 라이브러리가 변경되었을 때 필요한 파일들만 다시 컴파일합니다.
3. **빌드 순서 실행**: 이제 make 명령어는 올바른 순서로 빌드 단계를 실행합니다. 이는 종속성을 고려하여 컴파일, 링크, 및 기타 빌드 단계를 수행합니다. 종속성이 있는 파일은 변경되었을 때에만 해당 파일을 다시 빌드하고, 변경되지 않은 파일은 이전에 생성된 것을 사용하여 시간을 절약합니다.
4. **이진 이미지 생성**: 마지막으로, 모든 단계가 성공적으로 완료되면 make 명령어는 이진 이미지를 생성합니다. 이는 컴파일된 오브젝트 파일들을 링크하여 실행 가능한 이진 파일 또는 펌웨어 이미지를 생성하는 것을 의미합니다.
이처럼 make 명령어를 사용하면 임베디드 소프트웨어를 빌드하는 과정을 자동화하여 효율적으로 작업할 수 있습니다.
Makefile의 구성은 위와 같다.
Generate하고자 하는 target의 이름을 target 자리에 적고,
Target을 생성하기 위해 필요한 Prerequisites를 이어서 적고,
Target을 생성하기 위한 command를 Recipe 자리에 적는다.
command에서 사용할 수 있는 옵션sMakefile을 쉽게 적을 수 있도록 하는 Macro ; Structure을 만드는 거 아닐까?
GNU는 "GNU's Not Unix"의 재귀적인 약자로, 리처드 스톨만(Richard Stallman)이 1983년에 시작한 자유 소프트웨어 운동의 일환으로 개발된 운영 체제 및 관련 소프트웨어 프로젝트입니다.
GNU 프로젝트는 자유 소프트웨어의 개념을 중심에 두고 있으며, 소프트웨어를 사용, 이해, 수정 및 배포할 수 있는 자유를 보장하기 위해 노력합니다. 이러한 자유는 사용자의 컴퓨터 관련 자유에 관한 연구소(Free Software Foundation)가 정의한 것으로, 주요 요소로는 소스 코드 접근권과 수정, 재배포의 자유가 포함됩니다.
GNU 프로젝트의 주요 컴포넌트는 다음과 같습니다:
1. **GNU 운영 체제**: GNU 프로젝트의 핵심으로, Unix와 호환되는 운영 체제를 개발하는 것을 목표로 합니다. 하지만 리눅스 커널과 함께 사용되어 리눅스 시스템으로 알려지게 되었습니다.
2. **GNU 도구 체인**: 컴파일러, 디버거, 라이브러리, 텍스트 에디터 등의 여러 도구와 유틸리티를 포함한 개발 도구 체인입니다. 이러한 도구들은 대부분 GNU General Public License(GPL)을 따릅니다.
3. **GNU 라이브러리**: C 라이브러리와 같은 표준 라이브러리를 포함하여, 다양한 운영 체제 서비스를 제공합니다.
4. **GNU 프로젝트의 다른 소프트웨어**: GNU Emacs, GNU Make, GNU Bison 등의 다양한 소프트웨어가 GNU 프로젝트의 일부로 개발되었습니다.
GNU 프로젝트는 현재까지도 활발하게 진행되고 있으며, 오픈 소스 커뮤니티에 많은 영향을 미치고 있습니다. GNU의 철학은 소프트웨어가 자유롭고 사용자에게 통제권을 주는 것을 강조하며, 이를 통해 개발된 소프트웨어들은 전 세계적으로 널리 사용되고 있습니다.
디버깅
: 프로그램에서 잘못된 부분을 찾고 고치는 일
Error의 종류
1) Syntax error : 프로그램을 이해하지 못하는 오류. 실행 불가능.
2) Runtime error : 프로그램 실행 중에 에러 메세지와 함께 프로그램이 갑자기 종료되는 것.
→ 예) Indentation error, Index error, Name error, Zero division error
3) Semantic error : 프로그램이 에러 메세지 없이 실행되지만, 사용자가 기대하지 않은 실행 결과가 나오는 것.
임베디드 시스템에서의 디버깅
- On-Chip Debugger(open OCD)
: JTAG 및 SWD 인터페이스를 통해 임베디드 시스템을 디버깅하고 프로그래밍하는 포괄적인 지원을 제공하는 다재다능한 도구
디버거는..
• 실행을 중지하고 변수 값이나 호출 스택과 같은 프로그램의 실행 상태를 평가하기 위해 중단점을 활용합니다.
• 디버깅 장치는 일반적으로 JTAG(Joint Test Action Group) 표준에 따라 제조됩니다.
임베디드 타겟 장치에서 JTAG/SWD 기능에 접근하는 강력한 범용 오픈 소스 도구로는 OpenOCD(Open On-Chip Debugger)가 있습니다.OpenOCD는 임베디드 시스템 개발 커뮤니티에서 널리 사용되는 도구입니다. 임베디드 타겟 장치에 대한 디버깅과 인-시스템 프로그래밍을 제공합니다. 다음은 주요 기능 및 기능입니다.
1. **JTAG 및 SWD 지원**: OpenOCD는 임베디드 시스템의 디버깅에 일반적으로 사용되는 JTAG(Joint Test Action Group) 및 SWD(Serial Wire Debug) 프로토콜을 모두 지원합니다.
2. **다중 플랫폼 지원**: Linux, macOS, Windows 등 다양한 플랫폼에서 실행되며, 다른 운영 체제를 사용하는 개발자에게 적합합니다.
3. **넓은 장치 지원**: OpenOCD는 ARM 기반 마이크로컨트롤러 및 기타 임베디드 프로세서를 포함한 다양한 제조업체의 타겟 장치를 지원합니다.
4. **유연한 구성**: 사용자는 특정 요구 사항에 따라 디버깅 설정을 사용자 정의할 수 있는 다양한 구성 옵션을 제공합니다.
5. **다른 도구와의 통합**: OpenOCD는 Eclipse, Visual Studio Code, GNU Tools for ARM Embedded Processors 등과 같은 다양한 통합 개발 환경(IDE) 및 도구 체인과 통합될 수 있습니다.
6. **오픈 소스**: 오픈 소스로서 커뮤니티의 기여자들에 의해 적극적으로 유지보수되고 개발되며, 사용자는 소스 코드를 검토하고 개선을 기여하며 필요에 맞게 적응시킬 수 있습니다.
전반적으로 OpenOCD는 JTAG 및 SWD 인터페이스를 통해 임베디드 시스템을 디버깅하고 프로그래밍하는 포괄적인 지원을 제공하는 다재다능한 도구입니다. 신뢰성, 유연성 및 오픈 소스의 특성으로 많은 임베디드 개발자들에게 선택되는 도구입니다.
------------------------------------------------------------------------------------------------------------------------------------------------------- JTAG(Joint Test Action Group)와 SWD(Serial Wire Debug)는 임베디드 시스템에서 디버깅 및 프로그래밍을 위해 사용되는 통신 인터페이스입니다.
1. **JTAG (Joint Test Action Group)**: JTAG는 디바이스의 내부 상태를 접근하고 제어하기 위한 표준 인터페이스입니다. 이는 전자 기기의 디버깅, 테스트 및 프로그래밍에 널리 사용됩니다. JTAG 인터페이스는 여러 핀으로 구성되어 있으며, 시스템의 여러 컴포넌트에 접근하여 디버깅과 테스트를 수행할 수 있습니다. JTAG는 복잡한 디바이스의 내부 상태를 직접 읽고 제어할 수 있는 강력한 기능을 제공합니다.
2. **SWD (Serial Wire Debug)**: SWD는 ARM 프로세서 기반 시스템에서 사용되는 디버깅 인터페이스입니다. JTAG보다 적은 핀을 사용하여 디버깅 및 프로그래밍을 지원합니다. SWD는 단일 선으로 데이터와 디버깅 신호를 전송하므로 JTAG보다 적은 핀이 필요하고 회로를 간단하게 만듭니다. SWD는 ARM Cortex-M 시리즈 프로세서를 비롯한 다양한 ARM 기반 임베디드 시스템에서 널리 사용됩니다. 이러한 인터페이스들은 개발자가 임베디드 시스템의 내부 상태를 분석하고 디버깅하며, 프로그램을 다운로드하고 실행할 수 있도록 합니다. 임베디드 시스템의 개발 및 유지보수 과정에서 매우 중요한 역할을 합니다.
<임베디드 시스템에서의 디버깅의 종류>
1) Device Bring-up
- 하드웨어 전원이 들어오면 그 때부터 SW 책임이 된다.
- 전원 공급, 클럭 등 기본 동작을 확인한다.
- 부트 로더 등 가장 단순한 코드를 올려서 최소한의 기능을 확인한다.
- 프로세서와 메모리 정상 동작을 확인한다.
- 주변 장치 정상 동작을 확인한다.
Device bring-up은 임베디드 시스템에서 새로운 하드웨어 디바이스나 보드를 초기화하고 동작 가능한 상태로 만드는 과정을 말합니다. 이 과정은 하드웨어 설계가 완료되고 제조된 후에 발생합니다. 일반적으로 Device bring-up 과정에는 다음과 같은 단계가 포함될 수 있습니다:
1. **하드웨어 검증 및 확인**: 먼저 제조된 하드웨어가 제대로 동작하는지 확인합니다. 이는 회로 연결, 전원 공급, 신호 선 연결 등을 포함합니다.
2. **부트로더(Bootloader) 프로그램 개발 및 로딩**: 부트로더는 시스템의 초기화와 부팅을 담당하는 프로그램입니다. Device bring-up 단계에서는 보드에 부트로더를 로딩하고 실행할 수 있는 상태로 만듭니다.
3. **펌웨어 개발 및 플래싱**: 임베디드 시스템에서 실행될 펌웨어를 개발하고, 보드에 플래싱하여 실행 가능한 상태로 만듭니다.
4. **시스템 구성 및 초기화**: 하드웨어 및 소프트웨어의 초기화를 수행하여 시스템이 동작할 수 있도록 준비합니다. 이 단계에는 장치 드라이버 로딩, 인터럽트 설정, 메모리 할당 등이 포함될 수 있습니다.
5. **동작 테스트 및 디버깅**: 시스템이 동작하는지 확인하기 위해 기능 테스트를 수행하고, 필요한 경우 디버깅을 진행합니다. 이 과정에서는 시그널 분석기, 로직 분석기 등의 도구를 사용하여 하드웨어 및 소프트웨어의 동작을 확인할 수 있습니다.
Device bring-up은 새로운 하드웨어를 처음 사용할 때 매우 중요한 단계입니다. 하드웨어 및 소프트웨어의 문제를 조기에 발견하고 해결함으로써 제품의 개발 및 출시 일정을 준수할 수 있습니다.
2) 메모리 이슈
- memory leak
- null pointer 참고
- 할당 후 해제 후 다시 참고
- 배열 범위 밖으로 접근
- 자료형이 다른 포인터로 메모리 접근
디바이스의 실행 흐름
통상적으로,
부트로더( 시스템의 초기화와 부팅을 담당하는 프로그램 ) → 커널 → 메인 소프트웨어
멀티 프로세스를 지원하는 운영체제에서,
부트로더 → 리눅스커널 → 메인 프로세스
Q. 소프트웨어랑 프로세스 차이가 뭔데....?
프로그램 : 코드와 그 코드를 컴파일해서 생성된 실행 파일 ;실행하기 이전의 상태(정적인 상태의 소프트웨어)
프로세스 : 프로그램이 실행 상태에 있는 것 ;하나의 프로그램 실행 파일은 하나의 프로세스, 코드가 실행되고 메모리를 점유하며 프로세서의 리소스를 소모하고 있다(동적인 상태)
쓰레드 :프로세스 내부의 Task ;하나의 프로세스에 여러 개의 쓰레드가 존재, 프로세스는 프로세스 간 독립된 메모리 공간을 가지는데 반해, 쓰레드는 다른 쓰레드와 같은 메모리 공간을 점유
→ Multi-threaded process : latency를 숨기기 위해 사용
컨텍스트 :조금 전에 하던 일;운영체제가 시간을 분할하여 여러 프로세스, 혹은 쓰레드를 실행시킬 때 이전에 실행하고 있던 과거 프로세스 내지 쓰레드의 정보가 곧 컨텍스트이다. 운영체제가 프로세스들을 스케줄링 하면서 실행할 때, 하나의 프로세스에서 다른 프로세스로 실행 순서를 바꾸는 것을 Context Switching이라고 한다.